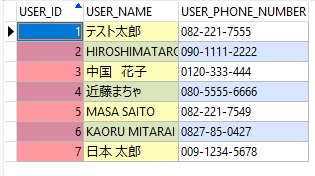
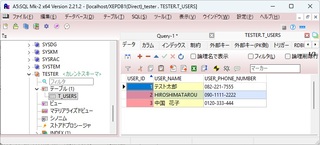
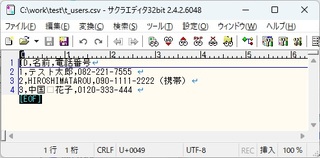
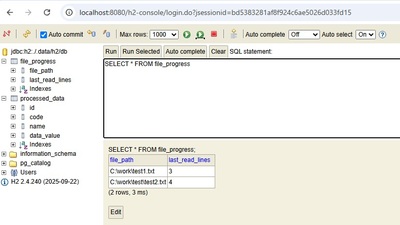
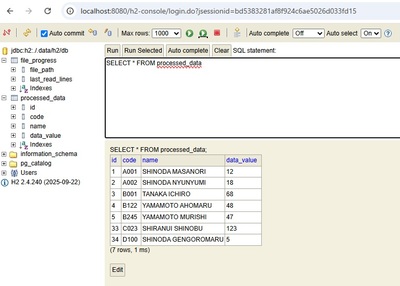
今まで作ってきた Spring Batch プログラムをコマンドラインから実行可能な JAR ファイルにしてみる。
Maven プロジェクトとして作っているので、以下の手順で。
プロジェクトを選択し、右ボタンメニューから「実行」→「Maven ビルド...」
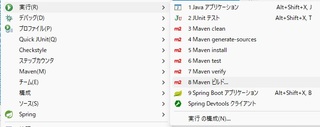
構成ダイアログが開くので、「ゴール」のところに「clean package」と入力
「ゴール(Goals)」には実行したい Maven のフェーズやプラグインの機能(コマンド)を指定する。
「clean package」は、「過去の生成物を削除し、新しく JAR や WAR などの配布ファイルを生成する」という指定。
「clean package」は、「過去の生成物を削除し、新しく JAR や WAR などの配布ファイルを生成する」という指定。
テストが不要なら、「clean package -DskipTests」。これで。JAR へのビルドだけが行われる。
「実行」ボタン押下
これでビルドが実行される。
[INFO] Scanning for projects...[WARNING] The requested profile "pom.xml" could not be activated because it does not exist.[INFO][INFO] [1m----------------------< [0;36mcom.example:BatchDB2CSV1 [0;1m >---------------------- [m[INFO] [1mBuilding BatchDB2CSV1 0.0.1-SNAPSHOT [m[INFO] from pom.xml[INFO] [1m--------------------------------[ jar ]--------------------------------- [m[INFO] Downloading from central: https://repo.maven.apache.org/maven2/org/apache/maven/plugins/maven-clean-plugin/3.5.0/maven-clean-plugin-3.5.0.pom[INFO] Downloaded from central: https://repo.maven.apache.org/maven2/org/apache/maven/plugins/maven-clean-plugin/3.5.0/<略>[INFO] Downloaded from central: https://repo.maven.apache.org/maven2/org/junit/platform/junit-platform-launcher/6.0.3/junit-platform-launcher-6.0.3.jar (246 kB at 2.2 MB/s)[INFO][INFO] -------------------------------------------------------[INFO] T E S T S[INFO] -------------------------------------------------------[INFO] Running com.netandfield.test. [1mBatchDb2Csv1ApplicationTests [m 16:26:53.111 [main] INFO org.springframework.test.context.support.AnnotationConfigContextLoaderUtils -- Could not detect default configuration classes for test class[com.netandfield.test.BatchDb2Csv1ApplicationTests]: BatchDb2Csv1ApplicationTests does not declare any static, non-private, non-final, nested classes annotated with @Configuration.<略>※「ゴール」に -DskipTests を記述していないので、実際に起動する形でテストが行われる. ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v4.1.0)<略>2026-07-14T16:26:58.105+09:00 INFO 19504 --- [BatchDB2CSV1] [ main] c.n.test.Listener.LogJobListener : ★Job started: exportJob2026-07-14T16:26:58.112+09:00 INFO 19504 --- [BatchDB2CSV1] [ main] o.s.batch.core.step.AbstractStep : Executing step: [exportStep]2026-07-14T16:26:58.816+09:00 INFO 19504 --- [BatchDB2CSV1] [ main] o.s.batch.core.step.AbstractStep : Step: [exportStep] executed in 704ms2026-07-14T16:26:58.821+09:00 INFO 19504 --- [BatchDB2CSV1] [ main] c.n.test.Listener.LogJobListener : ★Job finished: exportJob with status: COMPLETED2026-07-14T16:26:58.824+09:00 INFO 19504 --- [BatchDB2CSV1] [ main] o.s.b.c.l.s.TaskExecutorJobLauncher : Job: [SimpleJob: [name=exportJob]] completed with the following parameters: [{}] and the following status: [COMPLETED] in 717ms<略>[INFO] Downloaded from central: https://repo.maven.apache.org/maven2/org/vafer/jdependency/2.10/jdependency-2.10.jar (416 kB at 298 kB/s)[INFO] Downloaded from central: https://repo.maven.apache.org/maven2/com/google/code/findbugs/jsr305/3.0.2/jsr305-3.0.2.jar (20 kB at 12 kB/s)[INFO] Replacing main artifact C:\HogeHoge\pleiades\workspace\BatchDB2CSV1\target\BatchDB2CSV1-0.0.1-SNAPSHOT.jar with repackaged archive, adding nested dependencies in BOOT-INF/.[INFO] The original artifact has been renamed to C:\HogeHoge\pleiades\workspace\BatchDB2CSV1\target\BatchDB2CSV1-0.0.1-SNAPSHOT.jar.original[INFO] [1m------------------------------------------------------------------------ [m[INFO] [1;32mBUILD SUCCESS [m[INFO] [1m------------------------------------------------------------------------ [m[INFO] Total time: 34.209 s[INFO] Finished at: 2026-07-14T16:27:09+09:00[INFO] [1m------------------------------------------------------------------------ [m[WARNING] The requested profile "pom.xml" could not be activated because it does not exist.
これで、
C:\HogeHoge\pleiades\workspace\BatchDB2CSV1\target\BatchDB2CSV1-0.0.1-SNAPSHOT.jar
という JAR ファイルが作られた。
しかし、ビルド時にもすげえ色々ダウンロードしてくるなあ。こりゃ、インターネット環境のない場所じゃビルドできんわ(笑)
開発環境を完全にインターネットから切り離してるところって時々あるけど、時代にあってないよなあ・・・
じゃ、実行してみる。ちょっと場所が深いので、C:\work の下に移動しよう。
C:\work\BatchDB2CSV1-0.0.1-SNAPSHOT.jar
では、実行。
・・・の前に、ディフォルトで使われる java.exe はバージョンが古い。今回のバッチは Java 21 での実行を前提にしている。
C:\Users\hogehoge>java -versionjava version "1.7.0_09"Java(TM) SE Runtime Environment (build 1.7.0_09-b05_Fujitsu_10-30-12_12:00_patch)Java HotSpot(TM) Client VM (build 23.5.02_FUJITSU_MODIFIED-B04, mixed mode)
開発で使った Java 21 はここ。
C:\Users\hogehoge>C:\HogeHoge\pleiades\java\21\bin\java -versionopenjdk version "21.0.5" 2024-10-15 LTSOpenJDK Runtime Environment Temurin-21.0.5+11 (build 21.0.5+11-LTS)OpenJDK 64-Bit Server VM Temurin-21.0.5+11 (build 21.0.5+11-LTS, mixed mode, sharing)
環境変数(PATH)を直しちゃうと、他のプログラムがうまく動かなくなる可能性もあるので、とりあえずフルパス指定で実行しよう。
C:\Users\hogehoge>C:\HogeHoge\pleiades\java\21\bin\java -jar C:\work\BatchDB2CSV1-0.0.1-SNAPSHOT.jar models=1 modelName=未来電話. ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v4.1.0)<略>2026-07-14T16:47:55.110+09:00 INFO 18536 --- [BatchDB2CSV1] [ main] o.s.b.b.a.JobLauncherApplicationRunner : Running default command line with: [models=1, modelName=未来電話]2026-07-14T16:47:55.318+09:00 INFO 18536 --- [BatchDB2CSV1] [ main] o.s.b.c.l.s.TaskExecutorJobLauncher : Job: [SimpleJob: [name=exportJob]] launched with the following parameters: [{JobParameter{name='models', value=1, type=class java.lang.String, identifying=true},JobParameter{name='modelName', value=未来電話, type=class java.lang.String, identifying=true}}]2026-07-14T16:47:55.345+09:00 INFO 18536 --- [BatchDB2CSV1] [ main] c.n.test.Listener.LogJobListener : ★Job started: exportJob2026-07-14T16:47:55.360+09:00 INFO 18536 --- [BatchDB2CSV1] [ main] o.s.batch.core.step.AbstractStep : Executing step: [exportStep]2026-07-14T16:47:56.095+09:00 INFO 18536 --- [BatchDB2CSV1] [ main] o.s.batch.core.step.AbstractStep : Step: [exportStep] executed in 735ms2026-07-14T16:47:56.102+09:00 INFO 18536 --- [BatchDB2CSV1] [ main] c.n.test.Listener.LogJobListener : ★Job finished: exportJob with status: COMPLETED2026-07-14T16:47:56.104+09:00 INFO 18536 --- [BatchDB2CSV1] [ main] o.s.b.c.l.s.TaskExecutorJobLauncher : Job: [SimpleJob: [name=exportJob]] completed with the following parameters: [{JobParameter{name='models', value=1, type=class java.lang.String, identifying=true},JobParameter{name='modelName', value=未来電話, type=class java.lang.String, identifying=true}}] and the following status: [COMPLETED] in 757ms2026-07-14T16:47:56.113+09:00 INFO 18536 --- [BatchDB2CSV1] [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Shutdown initiated...2026-07-14T16:47:56.135+09:00 INFO 18536 --- [BatchDB2CSV1] [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Shutdown completed.
問題なく実行されたようだ。